Sentiment and Keyword Analysis Project
Overview
The Sentiment and Keyword Analysis Project is a data analysis endeavor that focuses on understanding sentiments and identifying keywords in textual data,
such as articles or blog titles. Using Python, NLTK (Natural Language Toolkit), and VADER (Valence Aware Dictionary and sEntiment Reasoner),
this project delves into sentiment analysis and keyword identification to extract valuable insights from text data.
It serves as a powerful tool for content analysis, market research, and understanding public sentiment.
Tasks
-
Data Import and Overview
- Import necessary libraries, including NLTK.
- Load textual data from an external source, such as an Excel file.
- Examine the structure of the dataset, including data types and column information.
-
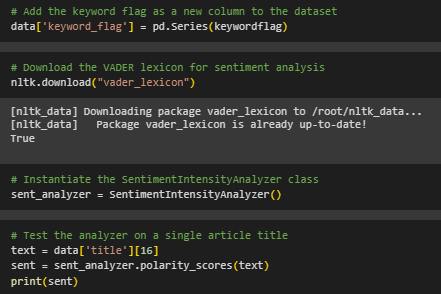
Sentiment Analysis
- Utilize VADER sentiment analysis to assess the sentiment of individual text entries.
- Calculate sentiment scores, including negative, positive, and neutral sentiments, for each entry.
- Store sentiment scores as new columns in the dataset.
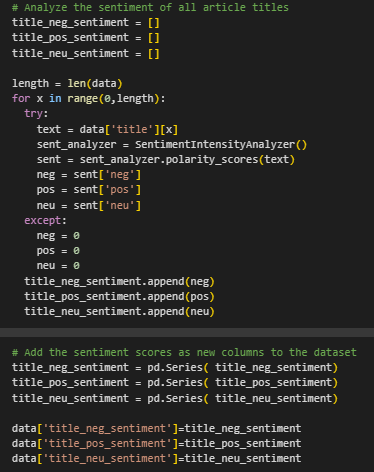
- Visualize and analyze sentiment trends in the dataset.
-
Keyword Identification
- Define a function to flag text entries containing specific keywords or phrases.
- Flag text entries based on the presence of keywords.
- Add the keyword flag as a new column in the dataset
- Analyze and visualize the prevalence of flagged keywords in the dataset.
-
Data Export
- Save the analyzed dataset, including sentiment scores and keyword flags, to a file for further analysis or reporting.
-
Data Visualization on Tableau
- Export the dataset to create an interactive dashboard on Tableau.
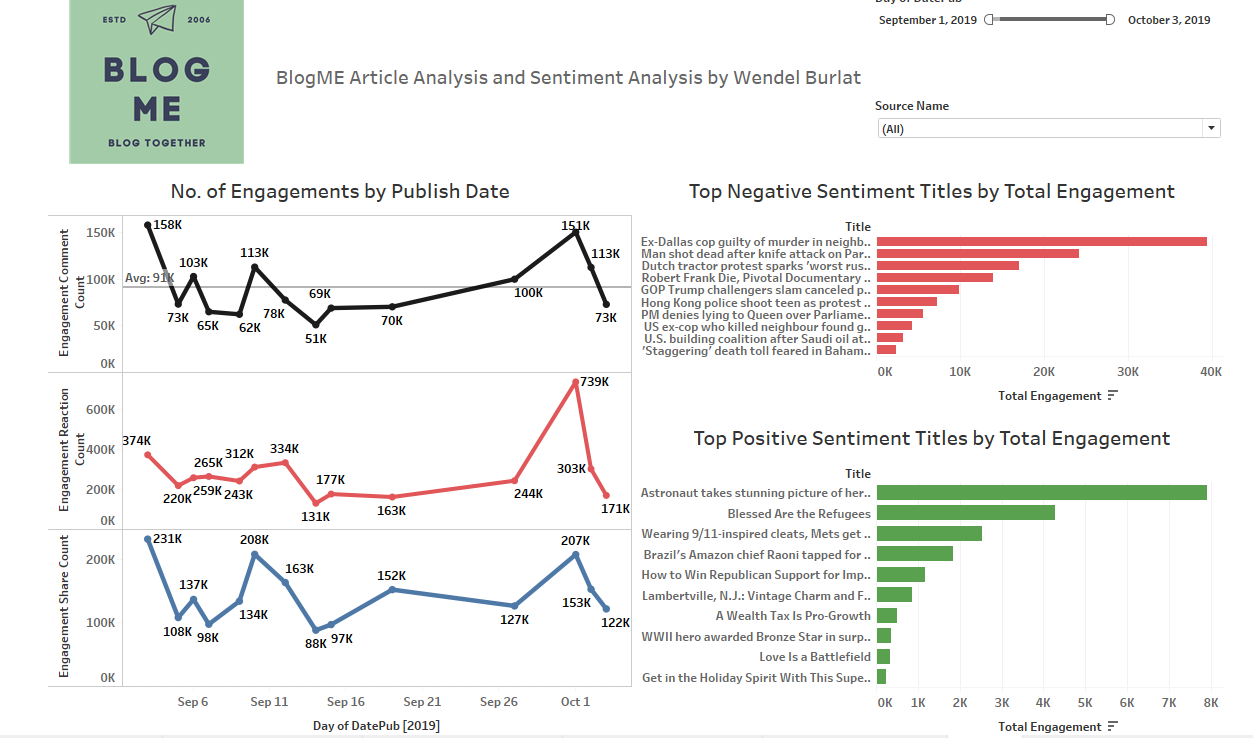
Project Outcome
The Sentiment and Keyword Analysis Project empowers users to gain insights from textual data. By conducting sentiment analysis, it helps understand the emotional tone of text entries, providing valuable information for market research, brand reputation analysis, and content optimization. Additionally, the keyword identification aspect aids in identifying relevant topics or trends within the text data, enhancing content curation and understanding user interests.
Note: This project contributes to informed decision-making within the sales and marketing domains, supporting organizations in achieving their sales targets, increasing profitability, and enhancing customer satisfaction. Please note that further analysis, interpretation of findings, and recommendations based on the insights gained from this project may be necessary in a real-world scenario.
View the code on GitHub:
Sales Analysis Project
View the Tableau Visualization on GitHub:
Tableau report file